基础知识
误差计算与前向传播
通过一个实例具体的体会神经网络的误差计算、误差反向传播和参数更新
前向传播
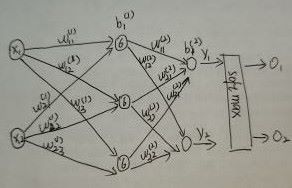
第一个隐层中的6表示一种激活函数(sigmoid)。
w_i_j表示i是前一层第i个节点于本层第j个节点的权重参数
前向传播的计算y_1的输出,在经过softmax激活得到一个有概率分布约束的输出数值。

同理O_2也是这样得到的。
损失计算
分类的损失一般使用交叉熵损失函数。函数中O_i是预测标签的值,O^*_i是真实标签的值。
多分类的交叉熵损失函数:
输入的是softmax函数输出的结果,所有事件的概率和为1,即输出的各个节点的概率是在同一个分布中的。在torch的交叉熵损失代码中已经加入了softmax
二分类的交叉熵损失函数
输入是sigmoid函数输出的结果,输出的各个节点的之间的概率数值是不相关的。
对于上面的网络我们的损失计算如下:
反向传播与参数更新
反向传播需要先求梯度,所以我们选择的函数尽量是可导且容易收敛。以更新第二层的w_11为例。
先求梯度: 
参数的更新是:
优化器
因为内存大小限制,我们不能一次性把train_set的数据用于训练需分batch,这样的话我们求梯度的方向就不一定是全局最优的方向,可以使用优化器解决这个问题。
SGD、Adagrad、RMSProp、Adam
常用知识
基本指标
混淆矩阵: 真实情况 预测结果 正例 反例 正例 TP(真正例) FN(假反例) 反例 FP(假正例) TN(真反例)
P = TP / (TP + FP)
Precision是针对预测结果而言的,含义是在预测结果中,有多少预测框预测正确了。
R = TP / (TP + FN)
Recall是针对原样本而言的,含义是在所有真实目标中,模型预测正确目标的比例。
FP 和 FN
假正例(False Positive,FP)和假反例(False Negative,FN)之间的互补性。
假正例和假反例分别位于不同的位置,且它们的数量之和反映了模型错误预测的总数。
假正例会增加预测为正类的样本数量,但其中实际为正类的比例会降低,因此会降低精确度。 假反例会减少被模型正确预测为正类的实际正类样本数量,因此会降低召回率。
一个假正例(即误诊)可能给患者带来不必要的焦虑和治疗负担。 一个假反例(即漏诊)则可能导致疾病进展和恶化,甚至危及患者生命。
因此在P-R的关系中两者也是互斥的。
pip更换镜像源
清华源
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple安装pytorch
常用的环境 CUDA12.1 + torch2.2
pip install torch==2.2.1 torchvision==0.17.1 torchaudio==2.2.1 --index-url https://download.pytorch.org/whl/cu121CUDA11.3+torch1.12
pip install torch==1.12.1+cu113 torchvision==0.13.1+cu113 torchaudio==0.12.1 --extra-index-url https://download.pytorch.org/whl/cu113检测Torch和CUDA
import torch
print(torch.cuda.device_count()) # 可用gpu数量
print(torch.cuda.is_available()) # 是否可用gpu无法指定GPU
该问题在旧版本的v8出现,解决方法如下: 在使用 --nproc_per_node 参数时,如果有四个 GPU,但不想使用 GPU 1,可以使用 CUDA_VISIBLE_DEVICES 环境变量来限制可见的 GPU。
CUDA_VISIBLE_DEVICES=0,2,3 python training.py --nproc_per_node=3
CUDA_VISIBLE_DEVICES=1 python train.py --nproc_per_node=1
在这个例子中,CUDA_VISIBLE_DEVICES 设置了可见的 GPU,排除了 GPU 1。然后,--nproc_per_node=3 指定了每个节点(即每台机器)上使用的 GPU 数量。这样就可以指定gpu训练了
onnxRuntime
可以使用netron查看该框架地计算图。