分类网络
Le-Net
第一个卷积神经网络,但是受到硬件条件的影响难以发挥出神经网络的优势。
Alex-Net
12年的Imagenet冠军算法。
亮点:
- 首次利用GPU进行网络加速训练
- 使用ReLU激活函数
- 使用LRN局部响应归一化
- 在全连接层中使用了Dropout随机失活,减少过拟合
VGG
14年Imagenet的定位冠军和分类第二。
亮点:通过堆叠多个3*3的卷积核替代更大的卷积核,感受野的大小是一样的但是参数量比较小。
Google-Net
14年Imagenet的分类第一。
亮点:
- 引入Inception结构(融合不同尺度的特征信息)
- 使用1*1的卷积核进行降维和映射处理
- 添加两个辅助分类器帮助训练
- 丢弃全连接层,使用平均池化层,达到减参的效果
Inception结构:有两个版本。将特征矩阵同时输入到不同尺度的卷积核和一个下采样中,并融合在一起。第二个版本即时在输入时通过1*1的卷积核进行降维操作达成减参目的.
class Inception(nn.Module):
# 这是一个v2版本的Inception
def __init__(self, in_channels, conv_1, conv_3_re, conv_3, conv_5_re, conv_5, pooling):
super(Inception, self).__init__()
self.branch_1 = ConvReLU(in_channels, conv_1, kernel_size=1)
self.branch_2 = nn.Sequential(
ConvReLU(in_channels, conv_3_re, kernel_size=1),
ConvReLU(in_channels, conv_3, kernel_size=3)
)
self.branch_3 = nn.Sequential(
ConvReLU(in_channels, conv_5_re, kernel_size=1),
ConvReLU(in_channels, conv_5, kernel_size=5)
)
self.branch_4 = nn.Sequential(
nn.MaxPool2d(kernel_size=3, stride=1, padding=1),
ConvReLU(in_channels, pooling, kernel_size=1)
)
def forward(self, x):
branch_1 = self.branch_1(x)
branch_2 = self.branch_2(x)
branch_3 = self.branch_3(x)
branch_4 = self.branch_4(x)
out = [branch_1, branch_2, branch_3, branch_4]
outputs = torch.cat(out)
return outputs辅助分类器:平均池化下采样(5*5)==>Conv 1==> 2FC softmax
LRN作用并不明显所以可以去掉。
class InceptionAux(nn.Module):
# 辅助分类器
def __init__(self, in_channels, classe_num, **kwargs):
super(InceptionAux, self).__init__()
self.averagePool = nn.AvgPool2d(kernel_size=5, stride=3)
self.conv = ConvReLU(in_channels, 128, kernel_size=1)
# 可以接入展开层
# self.f = nn.Flatten()
self.fc_1 = nn.Sequential(
nn.Linear(2048, 1024),
nn.ReLU(inplace=True)
)
self.fc_2 = nn.Linear(1024, classe_num)
def forward(self, x):
# Aux_1 input is B * 512 * 14 * 14
# Aux_2 input is B * 528 * 14 * 14
x = self.averagePool(x)
# Aux_1 pool is B * 512 * 4 * 4
# Aux_2 pool is B * 528 * 4 * 4
x = self.conv(x)
# Aux_1 conv is B * 128 * 14 * 14
# 展开
x = torch.flatten(x, 1)
x = f.dropout(x, 0.5, training=self.training)
x = self.fc_1(x)
x = f.dropout(x, 0.5, training=self.training)
x = self.fc_2(x)
return xRes-Net
15年冠军出自微软(何凯明)。
亮点:
- 超级深的网络结构(突破了1000层),但是不可能无限叠加,在上千层的时候还是出现了梯度(爆炸和消失)和退化问题
- 提出残差结构(residual模块)
- 舍弃Dropout,使用BN(Batch Normalization)
**Residual模块:**残差结构,是将前面输入加入到经过处理的里面,是相加需要保持channel一样,不同于Inception的concat计算。主要有两种残差结构。注意虚线的残差结构,在这个结构中进行通道改变和下采样。
class Residual(nn.Module):
expansion = 1
def __init__(self, in_channels, out_channels, stride=1, downsample=None):
super(Residual, self).__init__()
self.conv_1 = nn.Conv2d(in_channels, out_channels, kernel_size=3,
stride=stride, padding=1, bias=False)
self.BN_1 = nn.BatchNorm2d(out_channels)
self.conv_2 = nn.Conv2d(out_channels, out_channels, kernel_size=3,
stride=stride, padding=1, bias=False)
self.BN_2 = nn.BatchNorm2d(out_channels)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
def forward(self, x):
identity = x
if self.downsample is not None:
identity = self.downsample(x)
out = self.conv_1(x)
out = self.BN_1(out)
out = self.relu(out)
out = self.conv_2(out)
out = self.BN_2(out)
# 注意这里+是残差在激活
out += identity
out = self.relu(out)
return outBN(Batch Normalization)批归一化 :使得一个batch的feature map 满足均值为0方差为1的分布规律。加速网络收敛和提升准确率。注意:只需要在训练时使用就可以,通过model.train 和modl.pred去调整,这个使用和batch_size的大小,这个是加入在conv和激活函数之间,conv是不需加入偏置。
迁移学习:使用预训练模型的时候注意预处理的方式。
- 载入权重后训练所有参数
- 载入权重后只训练最后几层参数
- 载入权重后冻结参数,只训练我们在后续添加的模块参数
ResNext
新的Block,这个Block使用分组卷积。分组数是32
分组卷积就是卷积通道进行分组管理,这样能减参数。当每一个通道为一组时就是深度可分离卷积(DWconv)对于卷积层数少于3的效果是不是很好。实现的话加入groud约束好分组就好
Mobile-Net
这个是为嵌入式设备和移动设备提供推理能力的一种分类网络。
谷歌提出的,在嵌入式设备和移动设备的卷积神经网络。在效果相当的时候,参数量少了很多。
第一个版本
亮点:
- Deepwise Conv(DWconv)。卷积核的channel是为1的
- 增加超参数 a(卷积核格式) b(图像大小)
DW卷积就是输入的每一个通道有一个通道为1的卷积核负责,输出一组maps。
PW卷积是将DW的map,通过1*1卷积核进行整理
深度可分离卷积DW+PW卷积。
DW卷积核容易浪费,即卷积核参数大部分为0。
第二个版本
亮点:
- Inverted Residuals(倒残差结构)
- Linner Bottlenecks
倒残差结构:
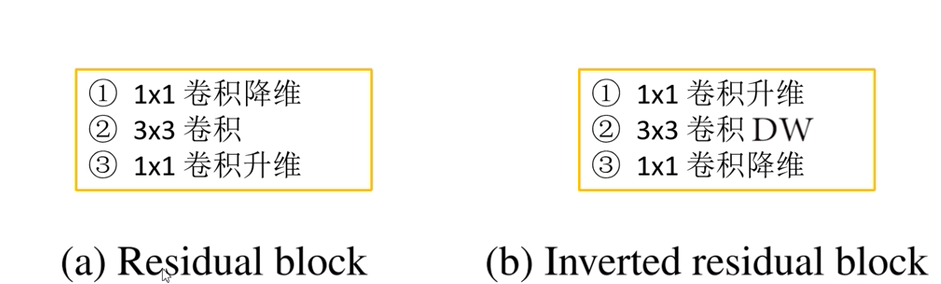
在激活函数中也有变化,在最后一个倒残差结构最后一个地方使用的是线性激活。这个结构并不是每一个结构都有分支连接shotcut。
# 倒残差
class InveredResidual:
def __init__(self, in_channels, out_channels, stride, expand_ratio) -> None:
hidden_channel = in_channels * expand_ratio
self.use_shotcut = stride == 1 and in_channels == out_channels
layers = []
# 针对第一个层,有没有拓展
if expand_ratio != 1:
# 1 * 1
layers.append(CBRonv(in_channels, hidden_channel, kernel_size = 1))
layers.extend([
# 3 * 3
CBRonv(hidden_channel, hidden_channel, kernel_size=3, stride=stride, groups=hidden_channel),
# 1 * 1 and liner 激活
nn.Conv2d(hidden_channel, out_channels, kenerl_size=1,bias=False),
nn.BatchNorm2d(out_channels),
])
self.conv = nn.Sequential(*layers)
def forward(self,x):
if self.use_shotcut:
return x + self.conv(x)
else:
return self.conv(x)第三个版本
亮点:
- 更新了Block,加入SE注意力和更换激活函数
- 使用了NAS搜索参数(Neural Architecture Search)
- 重新设计了耗时层结构
SE注意力通过avgpooling采样每个通道,得到一个向量,经过两个linner(channel-->channel/4-->channel)出来一个同纬的向量,这个向量表示的通道将的影响和相关性,将对应的权值与通道特征图相乘。
重新设计耗时层减少了第一层卷积核的个数,精减Last Stage
NAS搜索参数即在给定的search space(卷积核大小, 数量,步长)中搜索出网络合适的结构和超参数
随机搜索、RNN+RL、Datr方法(将每一层的选择融合在网络中,构建一个可微的loss)
Shuffle-Net
一个轻量化网络。
第一个版本亮点:
- 通道混淆 (channel shuffle)。
- 分组卷积和深度可分离。
通道混淆:将分组卷积和深度可分离卷积的每个groups进行关联。
def channel_shuffle(x: Tensor, groups: int):
batch_size, num_channels, height, width = x.size()
channels_pre_group = num_channels // groups
# 这里就是把序列分组,然后以每个组按序在重组的方式混洗,最后按照新的组展
# reshape
# [B[C[H,W],[]......]] ==> [B[G[C_1[H,W]...],[C_2[H,W]...]]]
x = x.view(batch_size, groups, channels_pre_group, height, width)
# 调换第一个维度和第二个维度的数据,然后在内存连续
x = torch.transpose(x, 1, 2).contiguous()
# flatten
x = x.view(batch_size, -1, height, width)
return x第二个版本:4个准则和新的块结构.。更关注内存访问开销,不只关注FloPs
轻量化的思路:(FLOPs不变,即层的参数量是确定的)
- 当conv的输入特征矩阵和输出特征矩阵channel相同是MAC最小(保持FLOPs不变)。
- 当Gconv的groups增大时(保持FLOPs不变),MAC也会增大。
- 网络设计的碎片化结构(多分枝)程度越高,速度越慢
- Element-wise操作(元素操作,+ 激活 shotcut等等)会带来的影响
根据这些准则,对v1的bock进行了调整
Efficient-Net
通过nas,得到考虑输入分辨率、网络深度和宽度(channel)对准确率的影响。博客
第一个版本
以往的经验:
- 增加深度能够获得更加丰富、复杂的特征并且能够很好的应用到其他任务但网络的训练更加困难,面临梯度消失等问题。
- 增加宽度能够获得更高细粒度的特征且容易训练,但宽度大深度浅的网络很难学到更深层次的特征。
- 增加网络输入的图像分辨率能够获取更高细粒度的特征模板,但对于非常高的输入分辨率,准确率的增加也会减小。并且增加计算量。
采用类似mobilenet的block结构,在细节上有变化。具体可以看源码。占用显存!
问题
- 训练图像分辨率很高时,训练速度很慢。
- 浅层使用DW卷积速度会变慢,是因为在浅层的dw与一些优化器不适应。
- 同等方法每个stage是次优的。
第二个版本
亮点:
- 引入Fused-MBConv模块
- 引入渐进式学习策略(训练更快)
- 使用更小的倍率因子和卷积核
Fused-MBConv的shotcut和dropout是同时存在。
这里的dropout随机失活是有点点不同。
渐进式学习可以好好利用一下。