误差计算与反向传播
通过一个实例具体的体会神经网络的误差计算、误差反向传播和参数更新
前向传播
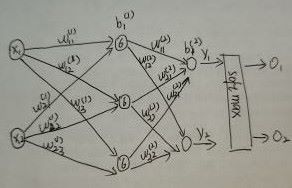
第一个隐层中的6表示一种激活函数(sigmoid)。
w_i_j表示i是前一层第i个节点于本层第j个节点的权重参数
前向传播的计算y_1的输出,在经过softmax激活得到一个有概率分布约束的输出数值。

同理O_2也是这样得到的。
损失计算
分类的损失一般使用交叉熵损失函数。函数中O_i是预测标签的值,O^*_i是真实标签的值。
多分类的交叉熵损失函数:
输入的是softmax函数输出的结果,所有事件的概率和为1,即输出的各个节点的概率是在同一个分布中的。在torch的交叉熵损失代码中已经加入了softmax
二分类的交叉熵损失函数
输入是sigmoid函数输出的结果,输出的各个节点的之间的概率数值是不相关的。
对于上面的网络我们的损失计算如下:
反向传播与参数更新
反向传播需要先求梯度,所以我们选择的函数尽量是可导且容易收敛。以更新第二层的w_11为例。
先求梯度: 
参数的更新是:
优化器
因为内存大小限制,我们不能一次性把train_set的数据用于训练需分batch,这样的话我们求梯度的方向就不一定是全局最优的方向,可以使用优化器解决这个问题。
SGD、Adagrad、RMSProp、Adam